
 Espen A. Werring
Espen A. Werring
 Erle Katrine Sivertsen
Erle Katrine Sivertsen
 Camilla Vislie
Camilla Vislie
 Andreas Stabell
Andreas Stabell
I denne artikkelen får du et innblikk i grunnleggende juridiske utfordringer med generativ kunstig intelligens (KI). I tillegg skal vi se nærmere på de to foreslåtte EU-rettsaktene, KI-forordningen og KI-ansvarsdirektivet. Til slutt får du en oversikt over noen av de rettslige problemstillingene som knytter seg til erstatningsansvar, personvern, cybersikkerhet og immaterialrett.
For et par uker siden uttalte vi oss i Advokatbladet om Thommessens bruk av kunstig intelligens ("KI"), hvor vi også oppfordret andre advokater til å ta i bruk dette. Samtidig som KI skaper mange muligheter og kan effektivisere en rekke prosesser i en virksomhet, reiser det også en rekke rettslige problemstillinger. Det oppstår særlig personvernrettslige og immaterialrettslige spørsmål. I tillegg kan KI medføre konsekvenser for IT-sikkerheten, og øker mulighetene for dataangrep og cyberkriminalitet. I denne artikkelen skal vi ta en nærmere titt på noen av problemstillingene som oppstår på disse rettsområdene i forbindelse med bruk av KI.
Det er uenighet knyttet til hvordan KI skal defineres, men KI kan grovt beskrives som digitale systemer som gjennom analyse og algoritmer, inkludert maskinlæring, kan tolke hendelser, støtte og automatisere beslutninger og å gjennomføre aksjoner. Felles for alle definisjoner er at KI på et vis utfører noe som minner om menneskelig intelligens. For tiden er det særlig generativ KI som er i vinden, og det er derfor generativ KI vi skal fokusere mest på i denne artikkelen.
Generativ KI er KI som er laget for å generere innhold, f.eks. tekst, bilder, video eller lyd. En kategori av generativ KI er store språkmodeller ("large language models (LLMs)"). Store språkmodeller er en type KI som er trent på en stor mengde data og som kan brukes til en stor mengde oppgaver. Et eksempel på en slik stor språkmodell er ChatGPT. Veldig enkelt forklart produserer ChatGPT svar ("output") ved å først analysere teksten brukeren skriver inn ("input") i tjenesten, for så å genere et svar som etter algoritmen er det mest sannsynlige svaret basert på konteksten og de dataene ChatGPT har trent på. ChatGPT genererer altså output steg for steg ved å forutsi neste ord basert på tidligere kontekst.
I denne artikkelen kan du lese mer om følgende:
- Grunnleggende utfordringer med generativ KI
- Lovregulering av KI
- Erstatningsansvar for feil og misbruk av KI
- Konfidensialitetsforpliktelser
- Personvernrettslige utfordringer
- Cybersikkerhet
- Krenkelse av immaterielle rettigheter ved bruk av KI
- Kan resultater skapt av KI være beskyttet av immaterielle rettigheter, og hvem blir i så fall innehaver av rettigheten?

Manglende åpenhet
Manglende åpenhet er en utfordring med generativ KI. Utviklerne ønsker ikke å utlevere kildekoden, og heller ikke å spesifisere hvilke kilder som er benyttet i treningen. Dette gjør det blant annet vanskelig å avdekke skjevheter i algoritmene ("bias"), og vanskelig for de registrerte å fullt ut forstå omfanget av behandlingen av personopplysninger.
Uriktige svar
ChatGPT produserer en mengde uriktige svar. Vi har for eksempel i flere tilfeller opplevd at ChatGPT henviser til ikke-eksisterende lovtekst og rettsavgjørelser. I tillegg går datasettet ChatGPT er trent på bare frem til september 2021. ChatGPT vil derfor ikke kunne svare om hendelser som har inntruffet etter dette. Dette medfører for eksempel at det ikke vil være mulig for ChatGPT å inkludere utviklinger i rettstilstanden etter 2021 i sine svar. Før man bruker output generert av ChatGPT, er det derfor nødvendig at en person med kompetanse innfor feltet man opererer på foretar en kvalitetssikring av outputen som er generert.
Skjevheter i algoritmene (bias)
Skjevheter i algoritmene, såkalt bias, kan oppstå når algoritmer systematisk og urettferdig favoriserer eller diskriminerer visse grupper. Dette kan blant annet skje på grunn av skjevhet i treningsdataene, i designfasen av utviklingen av algoritmen og gjennom trening på diskriminerende input fra brukerne. Konsekvensene av slike skjevheter kan føre til en forsterkning av et diskriminerende mønster basert på eksisterende menneskelige fordommer. Når det i tillegg mangler åpenhet rundt algoritmene og datasettene som er brukt i treningen, kan det være vanskelig å oppdage det diskriminerende mønsteret. Det bør derfor utvises forsiktighet med å bruke KI i beslutningsprosesser, f.eks. ved ansettelse og ved behandling av søknader om lån og forsikring.

Per dags dato finnes det ingen norske regler som regulerer KI direkte. EU-kommisjonen la imidlertid frem et forslag til en forordning om KI i 2021: "Proposal for a regulation of the European Parliament and of the Council laying down harmonised rules on artificial intelligence (Artificial intelligence Act) and amending certain union legislative acts" ("KI-forordningen"). I tillegg har EU-kommisjonen i 2022 fremmet et forslag til et direktiv som skal regulere sivilrettslig erstatningsansvar utenfor kontrakt når skade forårsakes av et KI-system: "Proposal for a Directive of the Eurpean Parliament and of the Council on adapting non-contractual civil liability rules to artificial intelligence (AI Liability Direktive)" ("KI-ansvarsdirektivet"). Ingen av de foreslåtte rettsaktene er endelig vedtatt, men vi skal i det følgende ta en nærmere titt på hva en endelig vedtakelse vil innebære for EU/EØS-retten, og dermed også norsk rett.
EU-kommisjonens forslag til KI-forordningen ("Artificial intelligence Act")
KI-forordningen skal klassifisere risiko for spesifikk bruk av KI, og sikre at man kan stole på KI-en man bruker. EU-kommisjonen foreslår en teknologinøytral definisjon av KI. I tillegg foreslår EU-kommisjonen en risikobasert tilnærming, hvor tanken er at jo høyere risiko bruken av KI utgjør, desto strengere bør bruken reguleres. I forslaget foreslår det å dele KI-systemer inn i fire risikonivåer:
- Uakseptabel risiko. Dette er skadelige KI-systemer som utgjør en klar trussel mot sikkerheten og grunnleggende rettigheter. Slike KI-systemer skal forbys etter KI-forordningen. Se KI-forordningen artikkel 5 for en nærmere definisjon av uakseptable KI-systemer.
- Høyrisiko. Dette er KI-systemer som innebærer en høy risiko for personers helse, sikkerhet og grunnleggende rettigheter, og er nærmere definert i KI-forordningen artikkel 6 og 7. Høyrisiko KI-systemer vil være tillatt, men for å sikre tillit og en høy grad av beskyttelse av sikkerhet og grunnleggende rettigheter, er det foreslått en rekke forpliktelser i KI-forordningen til KI-systemet (tittel II kapittel 2) og til leverandørene og brukerne av høyrisiko KI-systemer (tittel II kapittel 3).
Kravene til høyrisiko KI-systemer innebærer blant annet at det skal etableres et styringssystem for risiko, jf. artikkel 9. Videre stilles det krav til behandling av data for KI-systemer som trener med datasett, hvorav det blant annet gjelder et krav om å vurdere mulige skjevheter (bias), jf. artikkel 10. I artikkel 13 stilles det krav til åpenhet og informasjon til brukerne. I tillegg gjelder det krav om menneskelig tilsyn både ved utformingen og implementeringen av KI, jf. artikkel 14 og det stilles krav til cybersikkerhet, jf. artikkel 15.
- Begrenset risiko. KI-systemer som innebærer en begrenset risiko er kun pålagt et fåtall av forpliktelser, slik som åpenhetsforpliktelser etter artikkel 52.
- Lav eller minimal risiko. KI-forordningen pålegger ingen særlige forpliktelser for KI-systemer som innebærer lav eller minimal risiko.
I tillegg til forpliktelser knyttet til KI-systemene og til leverandørene og brukerne, inneholder forslaget regler om styringsfunksjoner og sanksjoner. Blant annet foreslås det i KI-forordningen artikkel 56 å opprette et Europeisk KI-råd (European Artifical Intelligence Board (EAIB)). Rådet skal gi råd og støtte til EU-kommisjonen. Videre foreslås det å etablere eller utnevne nasjonale tilsyn, jf. artikkel 59, som skal være meldermyndighet og drive markedsovervåkning.
I KI-forordningens artikkel 71 er det foreslått at virksomheter skal kunne ilegges gebyrer på inntil 30 000 000 euro eller 6 % av selskapets årlige omsetning på verdensbasis for brudd på regelverket. Størrelsen på gebyrene vil avhengig av hvilke artikler i KI-forordningen det foreligger brudd på.
Rådet for den europeiske union endringsforslag
Rådet for den Europeiske Union kom med sin uttalelse 6. desember 2022, hvor de blant annet foreslo å snevre inn definisjonen til å gjelde KI-systemer utviklet gjennom maskinlæringsteknikker og logikk- og kunnskapsbaserte teknikker, for å sikre at det oppstår et klart skille mellom KI-systemer og annen enklere programvare. Videre foreslår Rådet for den Europeiske Union at det inntas bestemmelser om generelle KI-systemer ("general purpose AI"), ettersom EU-kommisjonens forslag ikke inneholder dette. Rådet for den Europeiske Union foreslår også å klargjøre anvendelsesområdet til KI-forordningen, med blant annet eksplisitte unntak for nasjonal sikkerhet, forsvar og militære formål. I tillegg foreslår Rådet for den Europeiske Union å legge til nye bestemmelser for å sikre åpenhet og tillatte brukerklager.
Status og betydning for norsk rett
KI-forordningen er for tiden under behandling i de ulike EU-instansene. Det neste steget er at EU Parlamentet skal stemme over rapporten fra IMCO (Commitee on Internal Market and Consumer Protection) og LIBE (Committee on Civil Liberties, Justice and Home Affairs) i juni 2023, før de endelige forhandlingene kan starte for å komme til enighet med Rådet for den Europeiske Union om endelig tekst. EU-kommisjonens opprinnelige forslag til KI-forordningen regler som direkte regulerer generelle KI-systemer slik som ChatGPT, noe Rådet for den Europeiske Union foreslår at inntas. Det er derfor grunn til å anta at regler om dette vil inntas i den endelige forordningen. Forslaget til KI-forordningen er ikke markert EØS-relevant, men det er grunn til å tro at den vil bli EØS-relevant dersom KI-forordningen blir endelig vedtatt. Ettersom KI-forordningen er en forordning vil det innebære at den den må inkorporeres direkte i norsk rett slik den er.
EU-kommisjonens forslag til KI-ansvarsdirektivet ("AI Liability Directive")
Det foreslåtte KI-ansvarsdirektivet skal regulere det sivilrettslige erstatningsansvaret utenfor kontrakt for skade påført av KI. Slik lovgivningen er utformet i dag vil slike erstatningssaker behandles etter nasjonal lovgivning. De særlige karakteristikkene ved KI-systemer, slik som manglende åpenhet og autonom oppførsel, gjør det vanskelig å oppfylle beviskravet i erstatningsretten. KI-ansvarsdirektivet tar sikte på å bøte på dette, og å sikre lik regulering av erstatningsansvar for KI i EU. Det foreslåtte KI-ansvarsdirektivet fastsetter felles regler for fremleggelse av dokumentasjon for høyrisiko KI-systemer for å gjøre det mulig for saksøker å underbygge et eventuelt erstatningsansvar. I tillegg er det foreslått felles regler for bevisbyrden ved skyldansvar for skader forårsaket av et KI-system.
I tillegg foreslås det en presumsjon for at saksøkte ikke har utvist tilstrekkelig aktsomhet, dersom saksøkte ikke imøtekommer en nasjonal domstols anmodning om fremleggelse av dokumentasjon. Saksøkte vil likevel fortsatt ha mulighet til å motbevise dette. Både fysiske og juridiske personer kan være saksøkere etter det foreslåtte direktivet.

Ettersom KI-systemer ikke kan ha rettigheter og plikter på linje med individer og selskaper/organisasjoner etter nåværende lovgivning, oppstår det spørsmål om hvem som er ansvarlig for skade som er påført som følge av feil og misbruk av KI-systemer. I de fleste tilfeller vil det være tilvirkeren og/eller tilbyderen av KI-systemet som er ansvarlig, så fremt vilkårene for erstatning er oppfylt. Det er likevel ikke gitt at disse er ansvarlige i et hvert tilfelle. Generative KI-systemer som trener på brukernes input vil kunne utvikle seg selv og generere output som leverandøren ikke har kontroll over.
Det må skilles mellom skade forvoldt på en bruker av KI-systemet, og skade forvoldt på en tredjeperson utenfor kontrakt. Forholdet mellom tilbyderen og brukeren vil reguleres av det kontraktsrettslige erstatningsansvaret, mens skade forvoldt på en tredjeperson utenfor kontrakt vil falle inn under deliktsansvaret – dvs. erstatningsreglene som gjelder dersom skaden ikke har oppstått i forbindelse med et kontraktsforhold mellom skadevolder og den skadelidte.
Erstatningsansvar etter kontrakt forutsetter at det foreligger et avvik fra kontraktsmessig oppfyllelse som ikke skyldes forhold på kundens (brukerens) side. Selv om et KI-system genererer skadelig innhold er det ikke gitt at det foreligger et avvik fra kontraktsmessig oppfyllelse. For eksempel følger det av punkt 7 i OpenAI's "Terms of Use" en fraskrivelse av ansvar, hvor det heter at tjenesten leveres "som den er", og at OpenAI ikke garanterer at tjenestene vil være uforstyrret, korrekte og feilfri, og heller ikke at innhold er sikkert, ikke vil bli mistet eller endret. Dette innebærer blant annet at dersom skaden knytter seg til at ChatGPT har generert et feil svar vil ikke dette utgjøre et avvik fra kontraktsmessig oppfyllelse. Dersom det er påvist et avvik fra kontraktsmessig oppfyllelse, må det påvises et økonomisk tap, ansvarsgrunnlag og adekvat årsakssammenheng. Det vil som hovedregel være uaktsomhet som er det relevante ansvarsgrunnlaget.
For skade som er påført en tredjeperson utenfor kontrakt må de tre vilkårene for erstatning være oppfylt. Det må foreligge et økonomisk tap, ansvarsgrunnlag og adekvat årsakssammenheng. Det mest aktuelle ansvarsgrunnlaget vil være uaktsomhet, men det kan tenkes at det også i visse tilfeller kan ilegges et ulovfestet objektivt ansvar. På grunn av manglende åpenhet vil det kunne være utfordrende for skadelidte å påvise at det foreligger ansvarsgrunnlag.

En utfordring ved bruk av generativ KI med fritekstfelt er faren for at konfidensiell informasjon kommer på avveie. Brukerne står fritt til å skrive inn hva som helst i fritekstfeltet, inkludert konfidensiell informasjon. ChatGPT har et slikt fritekstfelt, og det følger det blant annet av personvernerklæringen til OpenAI at både ansatte i OpenAI og tredjeparter potensielt kan se opplysningene som skrives inn i ChatGPT.
Dersom brukeren ikke har slått av funksjonen om å bruke input som treningsdata, vil i tillegg den konfidensielle informasjonen potensielt kunne bli avslørt til andre brukere av ChatGPT. Forskning viser at det er mulig å få ut treningsdata fra noen språkmodeller gjennom bruk av chat-funksjonen. Selv om det foreløpig ikke er noen dokumenterte holdepunkter for at dette også gjelder ChatGPT er det sannsynlig at dette også vil kunne skje med ChatGPT, f.eks. ved at en bruker spør om spesifikk informasjon på et område hvor ChatGPT har tilgang til få kilder. Videre har Sam Altman, CEO i OpenAI, rapportert på Twitter 22. mars 2023 at på grunn av en "bug" i kildekoden kunne noen brukere av ChatGPT se tittelen på andre brukeres chat-historikk. Det er med andre ord mulig at også andre brukere av ChatGPT kan se andres input.
Risikoen for lekkasje og innsamling av konfidensiell informasjon ved ansattes bruk av generativ KI er bakgrunnen for at blant annet Apple nå forbyr ansatte fra å bruke ulike KI verktøy, inkludert ChatGPT og GitHub's Copilot (en KI programmeringsassistent). Virksomheter som bruker generativ KI, slik som ChatGPT, bør derfor ha gode interne rutiner og retningslinjer som sikrer at de ansatte er informert om at konfidensiell informasjon ikke skal skrives inn i ChatGPT.

Som nevnt står brukeren av en generativ KI med fritekstfelt fritt til å skrive inn hva som helst av informasjon, inkludert personopplysninger. Når input fra brukeren i tillegg kan brukes som treningsdata oppstår det en rekke personvernrettslige spørsmål og utfordringer. Dette førte blant annet til at det italienske datatilsynet i en kort periode forbød ChatGPT i Italia. Det italienske datatilsynet satte spørsmålstegn ved lovligheten av OpenAI's behandling av personopplysninger. For det første ved å tillate at ChatGPT produserer uriktig eller villedende informasjon, manglende informasjon til brukerne om hvordan de samler inn personopplysninger, manglende behandlingsgrunnlag og manglende adekvate forsøk på å forhindre barn under 13 år å bruke tjenesten. Ettersom OpenAI har imøtegått mange av kravene til forbedringer som det italienske datatilsynet fremsatte er forbudet nå opphevet. Selv om OpenAI har truffet mange tiltak for å sikre en bedre etterlevelse av GDPR er det fortsatt en rekke spørsmål og svakheter som gjenstår. I det følgende skal vi ta en nærmere titt på noen av problemstillingene som oppstår.
Behandlingsgrunnlag for input og trening med input i ChatGPT
Brukeren må etter GDPR artikkel 6 ha et behandlingsgrunnlag for personopplysninger brukeren putter inn i tjenesten. Dersom brukeren putter inn egne personopplysninger vil behandlingsgrunnlaget typisk være samtykke. Det kan imidlertid tenkes at en bruker putter inn andres personopplysninger, f.eks. i en prompt som ber ChatGPT om å utarbeide en avtale mellom to navngitte parter. Dersom brukeren skriver inn andres personopplysninger uten dennes samtykke, må brukeren basere behandlingen på et av de andre behandlingsgrunnlagene i artikkel 6.
For den videre behandlingen av personopplysningene vil OpenAI være behandlingsansvarlig, og må derfor ha behandlingsgrunnlag etter GDPR artikkel 6. Slik viderebehandling vil blant annet være lagring av personopplysninger, bruk av personopplysninger som treningsdata og gjenbruk av opplysningene ved generering av output. Da det italienske datatilsynet forbød ChatGPT anførte det italienske datatilsynet at oppfyllelse av kontrakt ikke var tilstrekkelig som behandlingsgrunnlag, og at OpenAI derfor enten måtte bruke samtykke eller berettiget interesse etter GDPR artikkel 6 nr. 1 bokstav a) og bokstav f). OpenAI har i ettertid oppdatert personvernerklæringen sin. Det følger nå av punkt 9 at OpenAI baserer seg på avtalen med brukeren for å behandle innloggingsinformasjon, input og teknisk informasjon. Videre bruker OpenAI berettiget interesse for å beskytte tjenesten mot misbruk, bedrageri og sikkerhetsbrudd, samt til å videreutvikle og forbedre tjenesten, inkludert trening av språkmodellen. OpenAI baserer seg dermed på berettiget interesse når de bruker input som inneholder personopplysninger som treningsdata.
De grunnleggende prinsippene for behandling av personopplysninger etter GDPR artikkel 5
Det er særlig bruk av personopplysninger som treningsdata i kombinasjon med den manglende åpenhet som er problematisk. Dette reiser en rekke spørsmål knyttet til de grunnleggende prinsippene for behandling av personopplysninger etter GDPR artikkel 5. De seks grunnleggende prinsippene for behandling av personopplysninger er: (a) prinsippet om lovlighet, rettferdighet og åpenhet, (b) prinsippet om formålsbegrensning, (c) prinsippet om dataminimering, (d) prinsippet om riktighet, (e) prinsippet om lagringsbegrensning, og (f) prinsippet om integritet og konfidensialitet.
Prinsippet om lovlighet, rettferdighet og åpenhet innebærer blant annet at den registrerte skal ha innsyn i hvordan personopplysningene behandles. Som nevnt innledningsvis er en av de grunnleggende utfordringene med ChatGPT at det er manglende åpenhet. Kildekoden er ikke tilgjengelig og det vil være vanskelig for den registrerte å sette seg inn i hvordan personopplysningene blir behandlet. Særlig gjelder dette når personopplysningene brukes til trening av språkmodellen. På grunn av manglende åpenhet er det vanskelig for den registrerte å fullt ut forstå hvordan personopplysningene blir behandlet.
Ved bruk av personopplysninger som treningsdata utfordres også særlig prinsippene om dataminimering og lagringsbegrensning. Når personopplysninger brukes som treningsdata vil personopplysningene stadig behandles på nytt og kunne brukes til å generere output. Etter GDPR artikkel 5 nr. 1 bokstav c) skal personopplysninger være adekvate, relevante og begrenset til det som er nødvendig for formålene de behandles for. Man kan spørre seg om det i det hele tatt er nødvendig å bruke personopplysninger til trening av ChatGPT. ChatGPT er først og fremst en språkmodell som genererer tekst. Det vil være mulig å levere tjenesten uten bruk av personopplysningene som er skrevet inn i fritekstfeltet. På nåværende tidspunkt har nok ikke ChatGPT løsninger for å skille ut personopplysninger fra annen input, men det kan tenkes at det er mulig å utvikle et filter som plukker ut personopplysninger som skrives inn i fritekstfeltet. Et avbøtende tiltak er at det nå er mulig å motsette seg at OpenAI bruker input til trening. Dette er imidlertid opp til hver enkelt bruker å slå av, og det vil derfor ikke avbøte for det tilfellet at andre som ikke har slått av denne funksjonen skriver inn personopplysninger om deg.
Prinsippet om dataminimering har også en side til hvor lenge personopplysninger oppbevares. Prinsippet om lagringsbegrensning følger av GDPR artikkel 5 nr. 1 bokstav e), hvor det heter at personopplysninger ikke skal lagres lenger enn der som er nødvendig. På nettsidene til OpenAI informeres det om at når chathistorikken er slått av slik at de ikke kan brukes til trening, vil OpenAI lagre nye samtaler i 30 dager og kun se på disse for å overvåke misbruk. Etter 30 dager blir samtalen slettet permanent. Når denne funksjonen ikke er slått av, og for øvrige personopplysninger innhentet på andre måter enn gjennom input, opplyser OpenAI i punkt 8 i personvernerklæringen at de vil lagre opplysningene så lenge det er nødvendig for å levere tjenestene eller for andre berettigede forretningsformål.
Retten til å bli glemt
Etter GDPR artikkel 17 har den registrerte en rett til å bli glemt. Dette innebærer at den registrerte har rett til å få personopplysninger om seg selv slettet dersom et av de opplistede forholdene i artikkel 17 nr. 1 bokstav a) til f) gjør seg gjeldene. Når personopplysninger brukes til trening av ChatGPT oppstår det spørsmål om det i det hele tatt er mulig med en reell etterlevelse av retten til sletting. Et KI-system kan ikke "glemme" treningsdata med mindre en slik funksjon er innebygget. Det er mulig å justere datasettet slik at den fokuserer på annen data, men den vil fortsatt ha tilgang til all informasjon som den har lært tidligere. På grunn av manglende åpenhet er det uklart om ChatGPT har innebygget funksjonalitet som gjør det mulig å glemme treningsdata. Selv om OpenAI nå har gjort det mulig for den registrerte å etterspørre sletting, er det uklart om det i realiteten er mulig å sikre fullstendig etterlevelse av GDPR artikkel 17.
Rett til retting
Et grunnleggende prinsipp i GPDR er at personopplysninger skal være korrekte og oppdaterte, jf. artikkel 5 nr. 1 bokstav d). For å sikre etterlevelse av dette prinsippet er den registrerte i GDPR artikkel 16 gitt en rett til å få uriktige opplysninger om seg selv rettet. Som nevnt innledningsvis produserer ChatGPT en del uriktige svar. Det kan være vanskelig for den registrerte å kunne sikre etterlevelse av retten til retting, særlig dersom personopplysninger brukes i output til andre brukere slik at den registrerte ikke er klar over at det genereres feil opplysninger.
Som det fremgår av de ulike problemstillingene som er gjennomgått i dette kapittelet har brukere i liten grad har kontroll over den videre behandlingen av personopplysninger de skriver inn i ChatGPT. Brukere bør derfor avstå fra å skrive inn personopplysninger i ChatGPT.

Generativ KI representerer også en risiko og trussel mot cybersikkerheten. For det første vil språkmodeller som ChatGPT gjøre det svært enkelt å produsere troverdig tekst uten skrivefeil til et phising-angrep. Det er derfor all grunn til å tro at phising-angrepene fremover vil bli vanskeligere å oppdage. For det andre er det fare for at ChatGPT påvirkes av onde aktører til å skrive ondsinnet kildekode. ChatGPT er trent til å overholde etiske retningslinjer, men det er stor sannsynlighet for at ChatGPT gjennom input i fritekstfeltet kan manipuleres til å skrive en kildekode som kan brukes til f.eks. hacking. Dette er kildekoder som allerede er tilgjengelige på darkweb, men vil nå kunne bli mer tilgjengelig gjennom ChatGPT.
Den foreslåtte KI-forordningen setter cybersikkerhet på agendaen, og stiller konkrete krav til høyrisiko KI-systemer. I fortalens punkt 51 i den foreslåtte KI-forordningen heter det at: "cybersecurity plays a crutial role in ensuring that AI systems are resilient against attempts to alter their use, behaviour, performance or compromise their security properties by malicious third parties exploting the system's vulnerabilities. Cyberattacks against AI systems can levarage AI spesific assets, such as training data sets (e.g. data poisoning) or trained models (e.g. adversarial attacks), or exploit vulnerabilities in the AI system's digital assets or the underlying ICT infrastructure. To ensure a level of cybersecurity appropriate to the risk, suitable measures should therefore be taken by the providers of high-risk AI systems, also taking into account as appropriate the underlying ICT infrastructure".
Videre heter det i artikkel 15 nr. 1 i den foreslåtte KI-forordningen at høyrisiko KI-systemer skal designes og utvikles slik at de oppnår et passende nivå av cybersikkerhet. Videre heter det i fjerde ledd at høyrisiko KI-systemer skal være motstandsdyktige mot forsøk fra uautoriserte tredjeparter på å endre KI-systemets bruk eller ytelse ved å utnytte systemets sårbarheter. De tekniske løsningene som skal sikre cybersikkerheten skal være tilpasset de relevante omstendighetene og risikoene. Videre heter det at de tekniske løsningene som adresserer KI-spesifikke sårbarheter skal i den grad det er hensiktsmessig inkludere tiltak for å forhindre og kontrollere angrep som prøver å manipulere treningsdatasettet, input som er designet for å få modellen til å gjøre feil, eller modellfeil.
Det stilles dermed konkrete krav som skal motvirke de risikoene som KI-systemene representerer for cybersikkerheten. I tillegg til disse foreslåtte kravene er en mulig rettslige konsekvens av at ChatGPT blir brukt til cyberkriminalitet, erstatningsansvar. Herunder oppstår det spørsmål om hvem som er ansvarlig for skade som er forvoldt i slike tilfeller.

Opphavsrett et særlig relevant tema
Bruk av generative KI-systemer som Stable Diffusion og ChatGPT reiser flere immaterialrettslige problemstillinger, særlig innenfor opphavsrettens område.
Opphavsrett til åndsverk gir rettighetshavere en enerett til å fremstille eksemplar av verket og gjøre verket tilgjengelig for allmennheten, jf. åndsverkloven § 3. I en digital sammenheng betyr dette blant annet at rettighetshaver har enerett til å fremstille digitale kopier av sitt verk og laste det opp på internett.
Ved bruken av KI-systemer utfordres rettighetshavernes enerett til åndsverk på flere måter, både i forbindelse med trening av KI og ved bruk av resultater som genereres av KI.
Bruk av opphavsrettsbeskyttede verk som treningsdata (input)
KI må trenes for å kunne gjennomføre gitte oppgaver. KI-systemer gjennomgår en treningsprosess, hvor data tilføres som informasjon til løsningen (input). Under en slik treningsprosess vil man, avhengig av den konkrete KI-tjenestens oppgaver og formål, hente data som er tilgjenelig online og/eller bruke allerede organiserte samlinger av data (datasett).
Under treningsprosessen vil det som hovedregel lagres midlertidige kopier av tekst- og data i KI-maskinens minne. Enhver midlertidig kopiering av slik data som omfatter opphavsrettsbeskyttede verk vil utgjøre eksemplarfremstilling som omfattes av rettighetshaverens enerett etter åndsverkloven § 3 (1) bokstav a. Med mindre rettighetshaver har samtykket til denne utnyttelsen, vil slik midlertidig eksemplarfremstilling derfor utgjøre inngrep i opphavsretten. Det samme gjelder retten til fotografiske bilder etter åndsverkloven § 23, hvor eksemplarfremstilling er avhengig av rettighetshavers samtykke. I tillegg vil uttrekk av data fra vernede databaser kunne krenke eneretten til databaser etter åndsverkloven § 24.
Bruk av opphavsrettsbeskyttede verk som input til KI-systemer har allerede resultert i flere søksmål. Selskapet bak tjenesten Stable Diffusion, Stability AI, har blitt saksøkt av Getty Images i både Storbritannia og USA for bruk av et datasett som angivelig inneholder 12 millioner av Gettys beskyttede bilder. Tre individuelle rettighetshavere har også anlagt et gruppesøksmål mot Stability AI, Midjourney og DeviantArt i California for bruken av deres opphavsrettsbeskyttede bilder i tjenesten Stable Diffusion.
For KI-systemer som baserer seg på en stor mengde ulike data, slik som ChatGPT, vil det være praktisk umulig for KI-utvikleren å identifisere og innhente samtykke fra den enkelte rettighetshaver for alle verk som brukes som treningsdata. Tekst- og datautvinning er nødvendig for å utvikle fungerende KI-tjenester, og på EU-nivå er det allerede vedtatt regler som kan føre til at slik aktivitet ikke er betinget av at samtykke er innhentet fra rettighetshaverne til de opphavsrettsbeskyttede verk som inngår i tekst- og datautvinningen. I direktiv 2019/790 om opphavsrett og nærstående rettigheter i det digitale indre marked mv. (DSM-direktivet) er det inntatt regler som gjør unntak fra opphavsretten ved såkalt tekst- og datautvinning. Det er antatt at disse unntakene vil få anvendelse ved trening av KI.
Av artikkel 3 i DSM-direktivet følger det at tekst- og datautvinning som omfatter eksemplarfremstilling av opphavsrettsbeskyttede verk vil være lovlig dersom aktiviteten skjer med et vitenskapelig forskningsrelatert formål, og at tilgangen til verkene i utgangspunktet er lovlig. Dette unntaket vil imidlertid være lite relevant for tekst- og datautvinning som skjer med et formål om å kommersialisere en KI-tjeneste.
Artikkel 4 regulerer derimot et unntak som innebærer at tekst- og datautvinning som skjer i kommersielt øyemed vil kunne være lovlig dersom
- tilgang til de opphavsrettsbeskyttede verkene i utgangspunktet er lovlig (typisk tekst- og bildemateriale som ligger åpent tilgjengelig på internett med rettighetshaverens samtykke),
- eksemplarfremstillingen av verkene ikke varer (lagres) lengre enn det som er nødvendig for å ivareta formålet med tekst- og datautvinningen, og at
- rettighetshaveren ikke uttrykkelig reservert seg mot at verket brukes som ledd i slik tekst- og datautvinning.
Artikkel 4 i DMS-direktivet vil forenkle KI-utviklernes trening av KI, ved at det ikke vil være nødvendig å innhente den enkelte opphaverens samtykke til bruk av verket i forbindelse med selve innhentingen av input. Samtidig gir regelen rom for at rettighetshaverne kan reservere seg mot bruk av verket, forutsatt at reservasjonen er gjort på en tilstrekkelig måte. For verk som ligger åpent på internett, presiseres det i direktivets fortale at en slik reservasjon bare vil være tilstrekkelig dersom reservasjonen er gjort i maskinlesbar form, for eksempel i metadata som er knyttet til det digitale verkseksemplaret, og i vilkår og betingelser for bruk på nettstedet hvor eksemplaret er tilgjengelig.
Ved at rettighetshaverne gis mulighet til å reservere seg mot bruk av verk til tekst- og datautvinning, vil i ikke artikkel 4 i DSM-direktivet medføre en nevneverdig innskrenking av opphavsretten. Det blir opp til rettighetshaveren å selv ta ansvar for å tydeliggjøre om det gis samtykke til bruk av verk eller ikke. Rettighetshavere, og særlig rettighetshavere som har eller forvalter rettigheter til større kataloger av verk, kan dermed fortsatt komme i en posisjon til å forhandle om vederlag for å gi sitt samtykke til bruk av verk som ledd i tekst- og datautvinning.
DSM-direktivet forventes å bli gjennomført i norsk rett i løpet av 2024. Inntil direktivet er gjennomført , er det ingen bestemmelser i åndsverkloven som tillater eksemplarfremstilling av åndsverk uten rettighetshavers samtykke. Gjeldende unntak om visse former for midlertidig eksemplarfremstilling i åndsverkloven § 4 vil trolig ikke komme til anvendelse for den form for omfattende data- og tekstutvinning som skjer ved trening av KI-systemer.
Fremstilling og bruk av resultater generert av KI (output) medfører risiko for inngrep i opphavsretten
Gjengivelse av deler av åndsverk og bearbeidelser
Til forskjell fra DSM-direktivets regler om tekst- og datautvinning ved trening av KI, er det så langt ikke foreslått regler for bruk av resultatene (output) som genereres ved bruk av KI-systemer. Et KI-system som baserer seg på input av opphavsrettsbeskyttede verk (jf. ovenfor), vil antagelig kunne produsere output som delvis består av et eller flere åndsverk i endret skikkelse. Også gjengivelser av deler av åndsverk, og bearbeidelser av verk hvor identiteten til originalverket fortsatt er fremtredende, vil kunne omfattes av opphavsretten til originalverket, jf. åndsverkloven § 3 (4) og § 6 (1). Risikoen for at et KI-system genererer output som omfattes av opphavsretten til eksisterende verk vil kunne avhenge av hvordan KI-systemet helt konkret er trent for å utelukkende generere output som ikke i for stor grad omfatter større deler av eller ligner eksisterende verk. For eksempel skal det trolig mye til før output generert av ChatGPT inneholder tilstrekkelig store deler av et åndsverk til å kunne kategoriseres som gjengivelse eller bearbeidelse. Dette er på grunn av det enorme datasettet ChatGPT er trent på, og måten teknologien for store språkmodeller fungerer (den gjetter neste bokstav basert på sannsynlighet). Dette er til forskjell fra Stable Diffusion, hvor det er utført studier som sammenlikner originalverk med output generert i Stable Diffusion som synes å indikere at en ikke kan utelukke at output generert ved bruk av denne tjenesten kan ligge for nært opp mot eksisterende verk. I den grad KI-systemer genererer output som omfattes av opphavsretten til et eller flere åndsverk, vil selve prosessen (dvs. genereringen av output) innebære en varig eller midlertidig eksemplarfremstilling av verket, jf. åndsverkloven § 3 (1) bokstav a. Denne eksemplarfremstillingen vil i seg selv gjøre inngrep i opphavsretten så lenge det ikke foreligger samtykke. Videre vil andres videreutnyttelse av slik output, eksempelvis opplasting av KI-generert output på internett, innebære en tilgjengeliggjøring i strid med opphavsretten, jf. åndsverkloven § 3 (2).
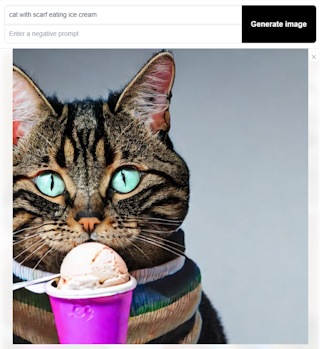
Eksempel fra generering av bilde i Stable Diffusion med søkeordene "cat with scarf eating ice cream". Stable Diffusion gir ingen informasjon om hvilken input som brukes for generering av bildene, og det er derfor vanskelig vurdere av om outputen er for likt et allerede eksisterende verk eller ikke.
Ansvar og sanksjoner
Et sentralt og uavklart spørsmål, er hvem som i opphavsrettslig forstand er ansvarlig for fremstilling av output som krenker opphavsrett – er det den enkelte bruker av KI-tjenesten eller virksomheten som eier/opererer KI-tjenesten?
Flere av tilbyderne av KI-tjenester har brukervilkår som pålegger brukeren av tjenesten ansvaret for krenkelser av tredjeparters immaterielle rettigheter. Det følger for eksempel av brukervilkårene til OpenAI at brukeren eier og alene er ansvarlig for bruken av output som genereres ved hans/hennes bruk av ChatGPT. Brukervilkårene er imidlertid ikke bindende for opphaveren, som i prinsippet vil kunne fremsette krav både mot tilbyderen av KI-tjenesten og/eller mot brukeren av KI-tjenesten.
Eksemplarfremstillingen som skjer ved genereringen av output er et resultat av brukerens instruks til KI-systemet om å fremstille et resultat. Den nærmere utformingen av outputen vil dels være avhengig av hvilke instrukser den enkelte bruker har gitt, og dels av hvilken input som er tilført KI-tjenesten av utviklerne som treningsdata. Brukeren har heller ikke kontroll over hvordan KI analyserer instruksjonene og genererer output fra dem. I opphavsrettslig forstand er det nok likevel mest nærliggende at brukeren i utgangspunktet er den som står for eksemplarfremstillingen.
Det er likevel ikke gitt at virksomhetene som tilbyr KI-tjenestene er ansvarsfrie. For det første er kan det tenkes at tjenestetilbyderne kan holdes ansvarlig på grunnlag av medvirkning. Videre har EU-domstolen gjennom tidene vist tendenser til å fravike etablerte opphavsrettslige synspunkter for å komme til et rimelig resultat. I denne sammenheng kan nevnes EU-domstolens avgjørelse i saken om The Pirate Bay fra 2017 (sak C‑610/15), hvor operatørene av torrentplattformen ble holdt ansvarlige for opphavsrettsinngrep, til tross for at det var den enkelte bruker som rent faktisk lastet opp opphavsrettsbeskyttet materiale på plattformen.
Hvis output generert fra KI brukes utenfor KI-tjenestens plattform, vil det være nokså klart at brukeren av outputen kan holdes ansvarlig for den eventuelle opphavsrettskrenkelsen en slik videreutnyttelse innebærer. Dette vil for eksempel gjelde opplasting av KI-genererte bilder eller tekst på brukerens egen nettside. Brukerne av KI-systemer må derfor være forberedt på å kunne holdes ansvarlig for opphavsrettsinngrep for fremstilling og videre bruk av output som er generert av KI. Dette gjelder selv om brukerne ofte vil være uvitende om at resultatene generert av KI-systemer krenker andres opphavsrettigheter.
Brukere av KI-generert output risikerer dermed også å kunne bli møtt med sanksjonskrav fra rettighetshavere, som krav om forbud mot videre utnyttelse eller krav om vederlag/erstatning. Etter åndsverkloven § 81 kan rettighetshavere kreve vederlag og/eller erstatning fra den som forsettlig eller uaktsomt har begått opphavsrettsinngrep, også den som i god tro har begått slikt inngrep kan etter omstendighetene bli pålagt å betale kompensasjon til rettighetshaver.
Sentrale spørsmål vil her kunne knytte seg til hvilke konkrete instrukser som brukeren har gitt til KI-tjenesten, hvilken informasjon om risiko som er gitt av tilbyderen av KI-tjenesten, og i det hele tatt hvilken grad av kontroll brukeren har hatt i forbindelse med genereringen av det opphavsrettskrenkende materialet. Det vil eksempelvis være mer nærliggende å sanksjonere en bruker som har instruert et KI-system om å bearbeide et eksisterende verk eller fremstille et eksemplar som "ligner eller er i samme stil som [kunstner/opphaver/verk]", fremfor den som har gitt helt generelle instruksjoner som ikke har sammenheng med bruken av eksisterende verk å gjøre. Det vil sannsynligvis også stilles strengere krav til virksomheters aktsomhet og kommersiell bruk av KI-generert innhold, enn for privatpersoners bruk.
Forslag om å innføre forpliktelser som sikrer mer transparens om omfanget av bruk av opphavsrettsbeskyttede verk
Som nevnt er det i dag vanskelig å identifisere hvilke data som brukes som input til KI-tjenester. For rettighetshavere er det derfor vanskelig å kontrollere om deres verk er en del av input, og for brukere blir det vanskeligere å kontrollere hvilken risiko de løper ved å bruke tjenestene. OpenAI har eksempelvis ikke gitt informasjon om hvordan og med hvilken data ChatGPT-4 ble opplært. Dette kan imidlertid bli endret ved vedtagelsen av KI-forordningen, hvor det er foreslått å innføre regler som pålegger KI-utviklerne åpenhetsforpliktelser. I foreslått artikkel 28b nr. 4 c) pålegges tilbydere av KI-systemer som ChatGPT en forpliktelse til å dokumentere og gjøre allment tilgjengelig en tilstrekkelig detaljert oversikt over hvilke treningsdata som er beskyttet av opphavsrett. Hvordan tilbyderne av KI-tjenester skal klare å overholde denne forpliktelsen, om det i det hele tatt er praktisk mulig, eller om det vil bety slutten for en del KI-systemer slik vi kjenner dem i dag, er sentrale spørsmål her.
Bruken av KI kan også utgjøre inngrep i øvrige immaterielle rettigheter
De fleste diskusjoner knyttet til bruk av KI og immaterielle rettigheter knytter seg til opphavsretten. Bruk av KI kan imidlertid også medføre krenkelser av andre immaterielle rettigheter.
Det er ikke utenkelig at en tjeneste som ChatGPT kan brukes til å gi brukere instruksjoner og veiledning som er egnet til å løse et gitt teknisk problem, for eksempel en fremgangsmåte for å fremstille et produkt. Er en slik fremgangsmåte patentbeskyttet, kan brukerens utnyttelse medføre i inngrep i andres patentrettigheter. Det samme er tenkelig på varemerkerettens og designrettens område, hvor en virksomhet tar i bruk et varemerke eller et design generert ved bruk av KI som krenker allerede eksisterende rettigheter.
Jurisdiksjon og lovvalgsspørsmål i inngrepssaker
For opphavsrettskrenkelser som skjer over internett, vil opphavere og rettighetshavere som har alminnelig verneting i EU/EØS vanligvis kunne anlegge erstatningssøksmål i sin hjemstat, jf. Luganokonvensjonen artikkel 5 (3) og EU-domstolens saker C-170/12 (Pinckney) og C-441/13 (Hejduk). For grenseoverskridendeinngrep som har tilknytning til land utenfor EU/EØS, vil også norske opphavere og rettighetshavere etter omstendighetene kunne anlegge søksmål for norske domstoler, jf. tvisteloven § 4-5 (3).
Lovvalgsspørsmålet i opphavsrettstvister som skjer over internett er noe mer komplekst. Utgangspunktet er at det landet der inngrepet skjer som bestemmer lovvalget. Dette kan resultere i ulike lovvalg for kopiering av verk til input for trening av KI, generering av output ved bruk av KI-tjenester, og videreutnyttelse (tilgjengeliggjøring på andre internettplattformer) av output generert av KI-tjenester.

Opphavsrett
KI-systemer som ChatGPT kan brukes til å generere alle typer tekster som artikler, historier, dikt, reklametekst og kildekoder. Ett av de store spørsmålene i forbindelse med fremveksten og bruken av KI har vært om slike resultater kan være opphavsrettslig beskyttet, og hvem som i så fall er innehaver av rettigheten.
For at et verk – en tekst, sang, bilde osv – skal være beskyttet av opphavsretten, må det gi uttrykk for "original og individuell skapende åndsinnsats", jf. åndsverkloven § 2. I dette ligger et krav om at åndsverket må være menneskeskapt. Den klare oppfatningen har derfor vært at KI-systemet i seg selv ikke kan være opphaver til et åndsverk, selv om resultatet som genereres er kreativt og originalt, og ikke bare en bearbeidelse eller kopi av tidligere verk.
Spørsmålet er dermed om brukeren kan få opphavsrett til verk som skapes ved hjelp av et KI-verktøy. I mange tilfeller vil KI bli brukt som et verktøy der brukerens egen kreativitet vil være en del av prosessen, i større eller mindre grad. For eksempel gir Sony's Flow Machines brukerne mulighet til å lage nye sanger basert på maskinlæring av eksisterende musikk og tar hensyn til brukernes preferanser, som hvilke instrumenter som skal brukes, tempo, osv.
ChatGPT kan instrueres til å lage artikler, dikt og historier, der brukeren underveis i prosessen kan instruere og veilede ChatGPT til å tilpasse og endre plottet, innhold, stil mv. Den rådende oppfatningen i Europa synes å være at verk skapt ved hjelp av KI-systemer, kan være beskyttet av opphavsretten, så fremt resultatet som kommer ut av KI-systemet er et resultat av brukerens egen intellektuelle frembringelse.
Hvor grensen går for mye menneskelig "input" i form av frie og kreative valg som er nødvendig for at verket skal være opphavsrettslig beskyttet er nokså uklart. Brukeren utøver nemlig ikke den fulle kreative kontrollen over hvordan KI-systemene tolker instruksjonene og generer materialet. Det er maskinen som til syvende og sist bestemmer hvordan instruksjonene skal implementeres i det endelige resultatet.
Saken om Zaraya of the Dawn fra US Copyright Office er illustrerende for problemstillingen:

Her forsøkte forfatteren bak tegneserien 'Zaray of the Dawn', Kristina Kashtanov, å søke opphavsrettigheter til tegneseriebildene illustrert ovenfor hos US Copyright Office – som administrere det nasjonale opphavsrettssystemet i USA. Bildene var generert av Midjourney, et KI-program for bildegenerering basert på instruksjoner. De genererte bildene ble deretter valgt ut, arrangert og delvis redigert av Kashtanov. US Copyright Office konkluderte med at Kashtanov ikke kunne få opphavsrett til de genererte bildene som sådan, men kun til den opprinnelige teksten og utvelgelsen og sammenstillingen av teksten og bildene som en helhet. Kashtanovs anførsel om at hvert enkelt bilde var resultatet av en kreativ prosess der et menneske veiledet KI-systemet gjennom hundrevis av mellomliggende bilder til et ønsket resultat ble oppnådd, førte ikke frem. US Copyright Office mente nemlig at selv om brukerens instrukser kan "påvirke" det genererte bilde, dikterer ikke mennesket et bestemt resultat, og det er ikke mulig å forutsi hva Midjourney vil skape på forhånd.
Siste ord i saken om Zarya of the Dawn er så vidt vi er kjent med ikke sagt. Det er foreløpig ingen tilsvarende praksis i Norge (eller EU), men med fremveksten av KI og mulighetene det bringer med seg har vi nok bare sett starten på slike saker.
Patentrett
Generative KI-systemer er i dag i stand til å løse en rekke komplekse problemer, og mange mener KI-systemer er i stand til å skape oppfinnelser som kan patenteres. Eksempelvis ble KI-systemet 'DABUS' kreditert som oppfinner i to patentsøknader inngitt av Stephen Taler i 2019 for henholdsvis en beholder for mat og drikke og en enhet og fremgangsmåte for å tiltrekke oppmerksomhet, som angivelig utelukkende var frembrakt av maskinen. USPTO, og senere også EPOs ankeinstans (Board of Appeal) i sak J08/20, har imidlertid avslått patentsøknadene med den begrunnelsen at en KI ikke kan angis som oppfinner i en patentsøknad.
Ingen tilsvarende saker har blitt prøvd her i Norge, men oppfatningen er nok at oppfinnelser utelukkende skapt av KI-systemer, ikke kan patenteres. Den rådende oppfatningen i Europa synes imidlertid å være at - for å fremme innovasjon - bør oppfinnelser som er skapt ved hjelp av KI, ikke utelukkes fra patentbeskyttelse.
Hvor grensen går for hvor hvilken kvalifiserende innsats et menneske må ha bidratt med i relasjon til KI-genererte oppfinnelser for å oppnå patentbeskyttelse, er imidlertid uavklart. Vil det å utelukkende eksponere tilfeldige data for KI-systemet, være tilstrekkelig dersom KI-systemet kommer opp med en oppfinnelse? Eller kreves det at personen benytter dataene med formål om at KI-systemet skal løse et bestemt teknisk problem? Man kanskje tenke seg at det oppfinneriske kan ligge i å formulere problemet, og at dersom problemstillingen i seg selv oppfyller kravet til oppfinnelseshøyde, vil mennesket kunne anses som oppfinner selv om KI-systemet finner løsningen på problemet. Spørsmålene er mange og avklaringer rundt dette vil bli nødvendig. Det er ikke usannsynlig at KI-systemer i fremtiden vil stå for en stor andel oppfinnelser, og i hvert fall gi betydelige bidrag til den teknologiske utviklingen.

Spotlight
Cybersikkerhet med Thommessen CyberHub
Bedrifter innen alle sektorer utsettes i økende grad for cyberkriminalitet. Vi har sammen med internasjonale cybersikkerhetseksperter opprettet Thommessen CyberHub – et fagforum der vi har invitert anerkjente cybereksperter til å delta. Sammen med våre partnere har vi som mål å øke våre klienters forståelse av de rettslige implikasjonene av cybertrusler, samt å bidra til bedre beredskap og mottiltak mot cyberhendelser.
Les mer


